##본 포스팅은 "데이터베이스 첫걸음 - 미크, 기무라 메이지" 책을 보고 요약한 것입니다.

지속성과 성능이 양립하는 구조
DBMS에서 데이터를 보존하는 기억장치는 대부분 하드디스크이다.
하드디스크에서 지속성을 실형하려면 쓰기를 전부 '동기화 쓰기'로 하면 좋겠지만, 데이터베이스의 쓰기는 기억장치의 임의 장소에 무작위로 액세스해서 쓰기를 수행하기 때문에 동기화 쓰기는 느려서 성능 면에서 실용적이지 않다.
그래서 지속성과 성능이 양립하도록 일반적으로 DBMS에서는 다음 구조를 사용한다.
- 로그 선행 쓰기(WAL)
로그 선행 쓰기의 기본 개념은 데이터베이스의 데이터 파일 변경을 직접 수행하지 않고, 우선 로그로 변경 내용을 기술한 로그 레코드를 써서 동기화하는 구조이다.
MySQL에서는 이로그를 InnoDB 로그라고 부른다. WAL에서는 다음과 같은 이점이 있다.
1) 디스크에 연속해서 쓰기 떄문에 무작위로 쓰는 것보다 성능이 좋다
2) 디스크에 쓰는 용량과 횟수를 줄일 수 있다
3) 데이터베이스 버퍼를 이용해 데이터베이스의 데이터 파일로의 변경을 효율성 높게 수행한다
- 데이터베이스 버퍼
커밋 시에는 WAL에 변경 내용을 쓰기 때문에 데이터 파일의 변경 내용은 트랜잭션이 커밋되면서 동시에 동기화할 필요가 없다. 그렇다고 트랜잭션마다 버퍼를 위해 비동기적인 쓰기를 하면 로그와 데이터 파일 간 일관성을 유지하기가 어렵다.
그래서 일반적인 DBMS에서는 '데이터베이스 버퍼'를 준비해 데이터 파일로의 입력을 데이터베이스 버퍼 경유로 일원화해서 단순화하고 있다. 이 때문에 효율적으로 데이터의 일관성을 유지할 수 있게 된다. MySQL의 경우 갱신의 흐름은 다음과 같다.

보통은 데이터 갱신 시 이 사이클을 반복한다. 즉, WAL과 버퍼 풀에 갱신을 반영해가며 데이터 파일보다 앞질러가는 형태가 되며, 체크 포인터에서 데이터 파일이 수정사항을 따라잡고 WAL과 버퍼풀이 선행해서 수정하기를 반복한다.

- 크래시 복구
WAL과 데이터베이스 버퍼, 데이터베이스 파일 3가지가 연계 플레이로 지속성을 담보하면서 현실적인 성능으로 DBMS가 동작하고 있다.
그럼 먼저 크래시가 발생한 경우에는 어떻게 복구하는지 보자. 크래시가 발생하면 다음과 같은 상태가 된다.

크래시 이후 MySQL 서버를 재시작하면 3과 1의 체크포인트 이후 갱신 정보를 사용해 데이터베이스 파일을 크래시 때까지 커밋된 최신 상태로 수정한다. 이 동작을 롤 포워드라고 한다.
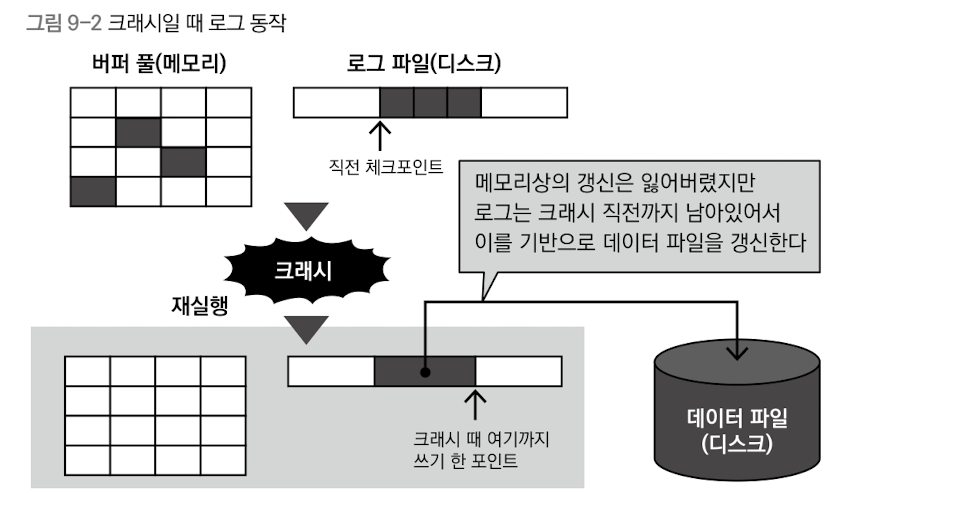
MySQL 서버를 재시작하는 것으로 복구할 수 있는 구조가 놀랍기는 하지만, 이와 같은 구조도 논리적인 파괴나 물리적인 파손에는 대응할 수 없다. 이와 같은 파손이나 파괴에 대응하려면 정상적으로 동작하고 있을 때 주기적으로 백업하고 이를 이용해 복원이나 복구하는 것이 좋다.
백업과 복구
1. PITR이란
데이터베이스의 데이터를 다양한 장애에서 지키려면 데이터베이스가 정상적으로 동작할 때 백업하고, 장애가 발생하면 백업으로 복원한다.
이렇게 하면 데이터베이스를 백업 시점의 상태로 되돌릴 수 있다. 하지만 단순히 백업시점으로 되돌릴 뿐 백업 후에 데이터베이스에서 수행한 갱신은 반영되지 않는다.
일반적인 DBMS에서는 데이터베이스에 실행된 갱신을 기록한 로그를 보존(Archive)해서 그것을 복원한 데이터베이스에 순차 반영해 백업 이후의 임의의 시점으로 복원할 수 있다. 이처럼 임의의 시점에서 데이터 변경을 포함한 복원을 PITR(Point-in-time Recovery'라고 부른다.

'아카이브 지정'은 PITR에 이용하는 로그는 대부분 앞에서 설명한 WAL을 이용한다.
이 때문에 WAL을 크래시 복구에만 이용한다면 체크포인트 이전의 로그는 불필요하게 되어 해당 디스크 영역은 삭제하거나 재이용할 수 있다.
하지만 이렇게 되면 PITR을 수행하고 싶을 때에 필요한 로그가 없는 사태가 발생하게 된다. 따라서 크래시 복구용으로는 불필요한 로그도 PITR용으로 보존이 필요할 수 있으며 이를 위한 모드가 '아카이브 지정'이다.
2. 백업의 3가지 관점
1) 핫 백업과 콜드 백업
핫 백업은 '온라인 백업'이라고도하며, 백업 대상의 데이터베이스를 정지하지 않고 가동한채로 백업 데이터를 얻는다.
콜드 백업은 '오프라인 백업'으로 불리며 백업 대상의 데이터베이스를 정지한 후 백업 데이터를 얻는다.

2) 논리 백업과 물리 백업
백업 데이터를 형식에 따라 구분하면 '논리 백업'과 '물리 백업' 2가지로 나눌 수 있다.
논리 백업은 SQL 기반의 텍스트 형식으로 백업 데이터가 기록되고, 물리 백업은 데이터 영역을 그대로 덤프하는 이미지로 바이너리 형식으로 기록된다. 오픈 소스 데이터베이스에서는 논리 백업을 다루는 도구가 준비되어있으며 이를 주로 이용하는 도구도 다수 있다.
이에 반해 크롤즈드 소스 데이터베이스에서는 물리 백업을 이용하는 경우가 많다. 논리 백업은 텍스트 형식을 따르고 물리 백업은 바이너리 형식을 따르고 있어서 아래와 같이 그에 따른 장단점이 있다.

3) 풀 백업과 부분 백업
백업 시 대상과 이에따른 데이터의 양을 중심으로 본다면 '풀 백업'과 '부분 백업'으로 구분할 수 있다. 풀 백업은 전체 백업이라고도 하며 데이터베이스 전체 데이터를 매일 백업하는 방식이다. 부분 백업은 우선 풀 백업을 한 후에 이후 갱신된 데이터를 백업한다.

위 그림은 처음에 풀 백업을 하고, 각각 1~3일 뒤의 상태를 백업과 복원할 때 어떤지를 나타낸다.
'Database' 카테고리의 다른 글
| SQL 첫걸음 31강~32강] 집합 연산과 테이블 결합 (0) | 2021.12.13 |
|---|---|
| SQL 첫 걸음 11장] 결과 행 제한과 수치연산 (0) | 2021.10.16 |
| 데이터베이스 첫걸음 4장] 데이터베이스와 아키텍쳐 구성 (0) | 2021.10.10 |
| SQL 첫걸음 9장~10장] 정렬하기 (0) | 2021.10.10 |
| 데이터베이스 첫걸음 3강] 데이터베이스 비용 (0) | 2021.09.26 |