
1. RISC vs CISC
instruction은 크레파스와 같다. 많은 색이 있을수록 좋다는 뜻이다.
하지만 크레파스 색이 많다고, 모든 색을 다 쓰는 건 아닌 것처럼 instruction도 많으면 전력소모가 커진다.
예전에는 instruction이 많으면 많은게 좋다고 판단을 하였지만 최근엔 잘 쓰는 inst만 잘 만들자는 추세이다
CISC(complex)는 원래 있었던 processor를 작동 시키기 위해 inst를 빼지 않고, 추가만 하였다. 그래서 호환성이 높다.
RISC(reduced)는 필요한 inst만 두었다
2. Instruction Set
"Set" : 하나로 처리할 수 있긴 하지만, 제한적이다
Instruction은 기계의 언어이다, 우리가 사용하는 고차원적인 언어보다 훨씩 원시적이며, 매우 제한적이다.
또한 섬세하지 못해서 for나 while같은 섬세한 작업은 기대할 수 없다
다른 computer(ISA)는 다른 inst의 집합들을 가지고 있다
3. The RISC-V Instruction Set
32개의 레지스터와 2^61개의 메모리 단어들로 이루어져있다
데이터를 메모리에 저장할 수도 있지만, 레지스터에 데이터를 저장하여 과정을 쉽고 빠르게 한다
RISC-V의 operands (피연산자)는 레지스터나 메모리가 되며,
operation(연산자)은 instruction이 된다.
4. 어떤 instruction이 올바른가?
규칙성과 간결성이 높은 성능을 만들어준다
5. Arithmetic Instructions example

code에 나와있는 것처럼 복잡한 연산을 한번에 지원하는 inst가 없으니, 펼쳐서 연산을 해야 한다.
t0와 t1은 임시값이다.
6. Register Operands example

피연산자, 연산자를 레지스터와 메모리에 저장한다
f, g, h, i, j가 레지스터에 있으니 대신 x19, x20으로 표현한다 (x는 레지스터라는 뜻이고, 뒤의 숫자는 레지스터 번호이다)
7. Register Operands
5번과 같은 Arithmetic instructions은 register 연산을 사용한다
레지스터는 x0부터 0x31까지 32개의 레지스터가 있고,
64-bit 데이터는 doubleword라고 불리며, 32-bit 데이터는 word라고 불린다
(역사적으로 32-bit를 word라고 해왔다)
8. Register Usage Conventions
레지스가 쓰여 온 관례이다
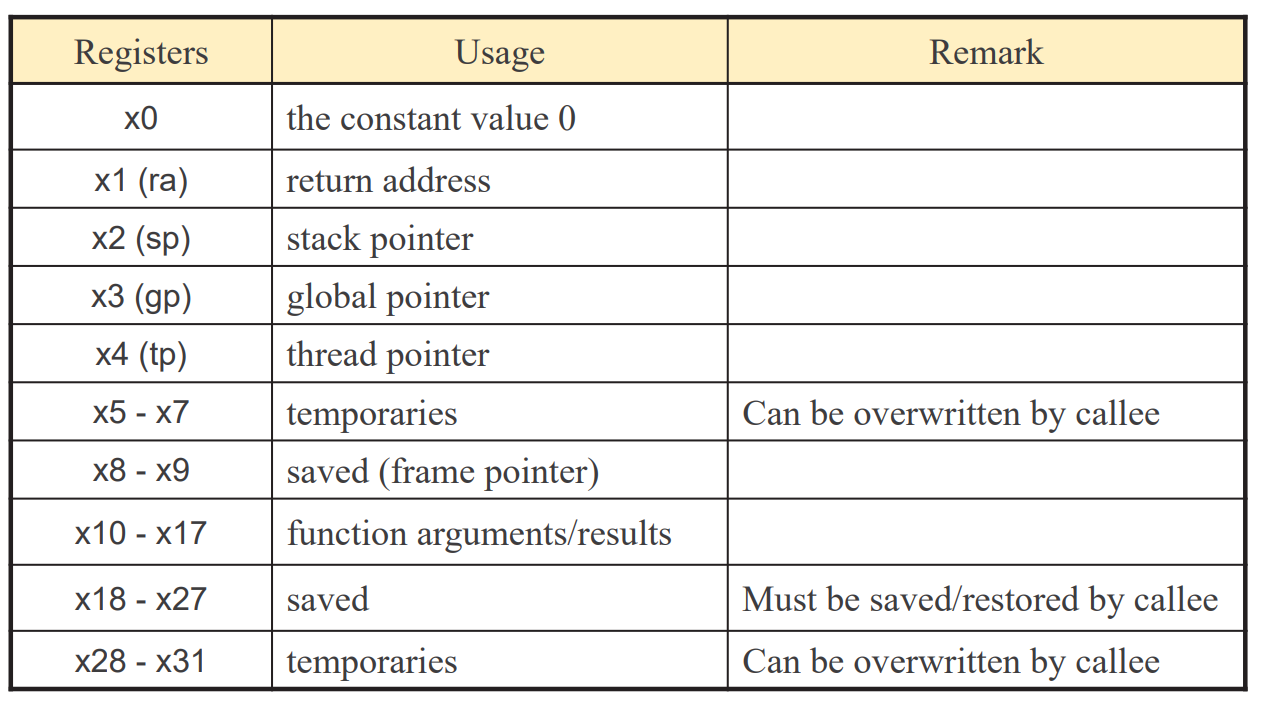
일반적으로 그렇게 한다는 의미이지, 꼭 그렇게 해야한다는 뜻은 아니다.
예를 들어 x1을 값을 저장하는 다른 용도로 써도 되지만, 오류의 위험이 있다, 그렇다고 x0에 저장할 수는 없다
x0은 상수0으로 사용되기 때문이다. ( if (t<0) 같은 경우 )
중요 : 0x1, 0x2, 0x10-0x17
9. Smaller numbers of Registers
Smaller is faster.
'값을 x9에서 가져와야지'라고 생각하며, 멀티플렉서로 x9를 뽑는다.
그러므로 레지스터 수를 최소화하는 게 시간이 단축된다.
크게 만들면 통과해야하는 게이트가 많아지며, 게이트가 많아지면 연산 시간이 길어진다.
또한 레지스터는 프로세서 안에 들어가야하므로, 작아야 한다.
그러므로 32개의 레지스터가 최적인 것이다.
10. Memory Operands
피연산자는 메모리에 들어갈 수도 있다.
메모리주소 또한 0이 시작 주소이다.
차례로 숫자가 증가하지만 1씩 증가가 아니고, 8byte씩 증가한다 (한 칸이 8byte라고 생각하면 됨)
int, char, float 등이 저장될 수 있으면 제일 큰 것에 집중 -> 8byte 공간을 차지
(하지만 이러한 방식이면 낭비공간이 발생하는 문제가 있다)
ina a[10]의 첫 원소가 메모리 1000~1004번지에 위치하지만 읽을 땐 1000번지만 읽고 그 뒤를 쭉 읽는다.
11. Memory Operands 2
배열, 구조체, 동적 데이터가 메모리에 저장된다.
레지스터에서 연산을 하기 위해서는, 1) 메모리로부터 레지스터로 값을 실어 날라야 한다.
2) 또 레지스터로부터 메모리로 값을 저장해야 한다.
레지스터에 값을 저장하는 것이 더 빠르지만, 실제로 저장할 수 있는 값의 수는 20여개 남짓이므로, 복합데이터는 메모리에 저장한다.
ex) a[i-4]같은 연산은 레지스터에서 허용되지 않는다.
12. Memory Operands : Big Endian vs Little Endian
최하위 비트를 어디서부터 저장하는 가에 따라 big, little을 결정한다
Big = 최하위 비트(LSB : less significant)를 높은 주소에 저장한다
Little = 최하위 비트를 낮은 주소에 저장한다
(낮은 수를 먼저두는 것이 연산에 더 편리하다)
13. Memory Operands : Example

ld = load double (double이니까 주소가 8씩 건너뛴다)
h는 레지스터, A[8]은 메모리에서 값을 가져온다
1) 시작주소 x22에서 64(8*8)만큼 떨어진 곳에서 값을 가져와서 x9에 실어 나른다
2) x9와 x21을 더해서 x9에 넣는다, x21은 h를 의미하는 게 된다
3) x9를 x22에서 96(8*12)만큼 떨어진 공간에 넣는다
실제로 주소는 매우 길지만, 최대한 간단히 표기한다.
14. Registers vs Memory Operand
레지스터는 메모리보다 더 빨리 접근할 수 있다.
메모리의 데이터를 이용하여 연산하는 것은 load와 store가 필요하다
컴파일러는 변수를 가능한 레지스터를 이용해야만 한다 (덜 사용하는 변수는 메모리로 내보낸다, 버린다)
(이 부분은 컴파일러가 알아서 하도록 내버려 둔다)
15. Immediate Operands
g = g + 4 ;
위 연산은 상수인 4를 이용한 연산이다.
프로그래머는 '상수와의 연산이 더 간단하겠지?'라고 생각하지만 그리 쉽지는 않다.

상수와의 연산은 그냥 연산과 inst가 다르기에 add가 아닌, addi이다.
첫번째 그림과 두번째 그림은 같은 의미이지만, addi로 두번째 그림의 복잡한 연산을 한번에 할 수 있다.
첫번째 그림에서 x22는 레지스터를 의미한다, 즉 g이다.
두번째 그림을 보면 ld가 있는데, x9레지스터에 상수 4를 가져와서 저장한다는 의미이다
그 후에 add를 한다.
16. Immediate Operands : Engineering View
Make the common case fast
작은 상수들(4같은)은 common한 숫자이다.
addi같은 immediate operand는 load inst를 사용하지 않는다
그러므로 addi같은 inst를 따로 두는 것이 편리하다
add는 모두 변수인 경우 -> add x22, x22, x9
addi는 상수 계산인 경우 -> addi x22, x22, 4
피연산자를 구분하는 것은 instruction을 보고 구분해야만 한다
17. sign extension (부호 확장)
값을 보존하기 위해 부호를 고려하여 적절히 bit를 확장시켜야 한다.
양수면 0으로, 음수면 1로 채우는 등의 방법을 사용해야 한다. 즉 부호를 앞의 비어있는 모든 bit에 복제하는 방식이다.
'System Structure' 카테고리의 다른 글
| [Chapter 5] Large and Fast : Exploiting Memory Hierarchy (0) | 2019.11.26 |
|---|---|
| 컴퓨터 구조 1 : 컴퓨터 시스템 구조 (0) | 2019.09.10 |