
##본 포스팅은 "SQL 첫걸음 - 아사이 아츠시" 책을 보고 요약한 것입니다.

인덱스
인덱스는 테이블에 붙여진 색인이라 할 수 있다.
인덱스의 역할은 검색속도의 향상이다.
여기서 '검색'이란 SELECT 명령에 WHERE 구로 조건을 지정하고 그에 일치하는 행을 찾는 일련의 과정을 말한다.
테이블에 인덱스가 지정되어 있으면 효율적으록 검색할 수 있으므로 WHERE로 조건이 지정된 SELECT 명령의 처리 속도가 향상된다.
데이터베이스의 인덱스에는 검색 시에 쓰이는 키워드와 대응하는 데이터 행의 장소가 저장되어 있다.

인덱스는 테이블과의 별개로 독립된 데이터베이스 객체로 작성된다.
목차밖에 없는 책은 없는 것처럼, 인덱스는 테이블에 의존하는 객체라 할 수 있다.
그래서 대부분의 데이터베이스에서는 테이블을 삭제하면 인덱스도 같이 삭제된다.
검색에 사용하는 알고리즘 : 이진 탐색
데이터베이스의 인덱스에 스이는 대표적인 검색 알고리즘으로는 '이진 탐색'이 있으며,
이 방법데 사용되는 구조는 '이진 트리'이다.
Full Table Scan
인덱스가 지정되지 않은 테이블을 검색할 때는 [풀 테이블 스캔]이라 불리는 검색 방법을 사용한다.
모든 값을 처음부터 차례로 조사해나가는 것이다.
Binary Search
이진 탐색은 차례로 나열된 집합에 대해 유효한 검색 방법이다.
처음부터 순서대로 조사하는 것이 아니고 집합을 반으로 나누어 조사하는 검색 방법이다.

풀 테이블 스캔을 한다면 데이터 수에 비례해 비교횟수도 늘어난다.
그에 비해 이진 탐색은 데이터 수가 배가 되어도 비교 횟수는 1회밖에 늘어나지 않는다.
이진 트리
이진 탐색은 고속으로 검색할 수 있는 탐색 방법이지만, 데이터가 미리 정렬되어있어야한다.
하지만 테이블 내의 행을 언제나 정렬된 상태로 두는 것은 힘들다.
일반적으로는 테이블에 인덱스를 작성하면 테이블 데이터와 별개로 인덱스용 데이터가 저장장치에 만들어진다.
이 때 인덱스용 데이터는 이진 트리라는 데이터 구조로 작성된다.
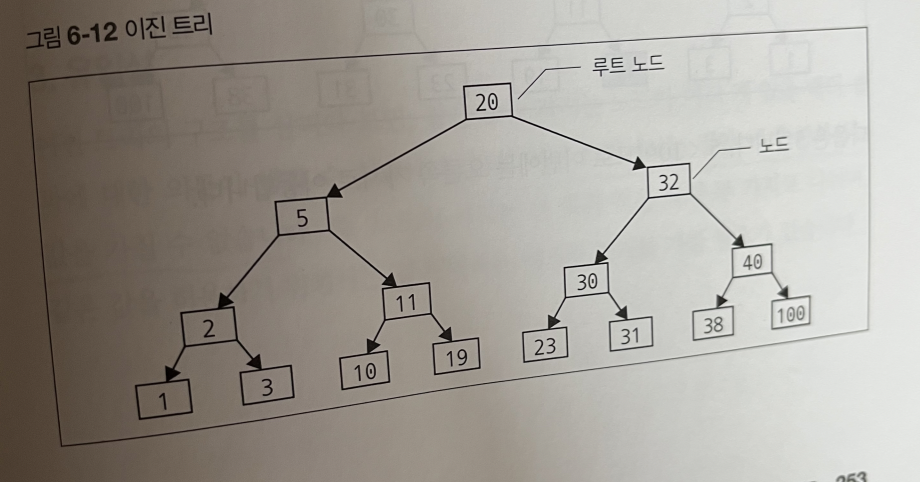
트리는 '노드'라는 요소로 구성되며, 각 노드는 두 개의 가지로 나뉜다.
노드의 왼쪽은 작은 값으로, 오른쪽은 큰 값으로 나뉘어져있다.

*이진 트리에서는 집합 내에 중복하는 값을 가질 수 없다.
인덱스 작성과 삭제
1. 인덱스 작성
#CREATE INDEX 인덱스명 ON 테이블명(열명)
CREATE INDEX index ON table1(no);인덱스를 작성할 때는 해당 인덱스가 어느 테이블의 어느 열에 관한 것인지 지정할 필요가 있다.
2. 인덱스 삭제
#DROP INDEX 인덱스명 ON 테이블명
DROP INDEX index ON table1;테이블을 삭제하면 테이블에 작성된 인덱스도 자동으로 삭제된다.
3. EXPLAIN
인덱스를 작성해두면 검색이 빨라진다.
작성한 인덱스의 열을 WHERE 구로 조건을 지정하여 SElECT 명령으로 검색하면 처리속도가 향상된다.
한편, INSERT 명령의 경우에는 인덱스를 최신 상태로 갱신하는 처리가 늘어나므로 처리속도가 조금 떨어진다.
위의 CREATE 예제처럼 no 열에 해당하는 SELECT 명령은 인덱스를 사용해 빠르게 검색할 수 있다.
SELECT * FROM table1 WHERE a = 'a';이 때 실제로 인덱스를 사용해 검색하는지를 확인하려면 EXPLAIN 명령을 사용한다.
#EXPLAIN SQL명령문
EXPLAIN SELECT * FROM table1 WHERE a = 'a';이 SQL 명령은 실제로는 실행되지 않지만, 어떤 상태로 실행되는지를 데이터베이스가 설명해줄 뿐이다.

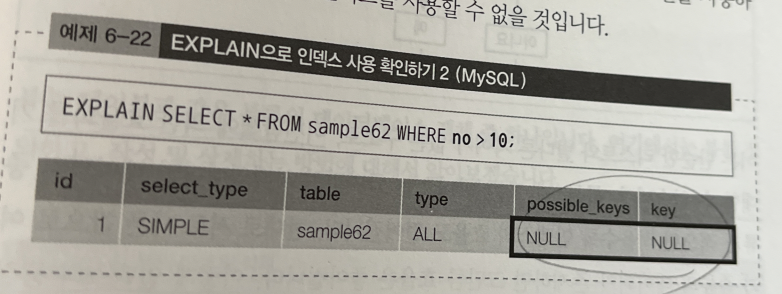
possible_keys에는 사용될 수 있는 인덱스가 표시되며, key는 사용된 인덱스가 표시된다.
내부처리에서는 SELECT 명령을 실행하기에 앞서 실행계획을 세운다.
실행 계획에서는 '인덱스가 지정된 열이 WHERE 조건으로 지정되어 있으니 인덱스를 사용하자' 또는 '익덱스를 사용할 것인지 말지 결정하자'와 같은 처리가 이뤄진다.
EXPLAIN 명령은 이 실행게획을 확인하는 명령이다.