
##본 포스팅은 "데이터베이스 첫걸음 - 미크, 기무라 메이지" 책을 보고 요약한 것입니다.

집합과 함수를 살펴보자
다양한 데이터가 테이블에 저장되므로 '테이블 설계'의 기준에 따라 작성해야한다.
'테이블 설계' 시 중요한 것이 '집합'과 '함수'이다.
여기서 테이블은 집합이며 함수이다.
모든 데이터는 테이블에 포함되고,
데이터가 복잡하고 대규모가 되면 데이터를 담는 테이블은 수천개가 되며, 테이블 설계가 허술하게 되어있다면 데이터에 모순이 생기는 문제가 끊이지 않고 일어난다.
[관계형 데이터베이스가 주류가 된 이유]
'Garbage in, garbage out'라는 말대로, 데이터베이스에서의 데이터 저장은 매우 중요하다.
많은 데이터베이스 종류 중에, 관계형 데이터베이스가 표준 데이터베이스 제품이 된 이유 중 하나는
데이터의 정확성을 높이기 위한 '설계 노하우'가 매우 발달했기 때문이다.
테이블 설계는 서버나 스토리지 같은 물리층과 관계없이 독립적으로 작성하는 것이 가능해서 '논리의 세계에서 결정된다'라고 간주하기에
테이블 설계를 '논리 설계'라고도 부른다.
[테이블]

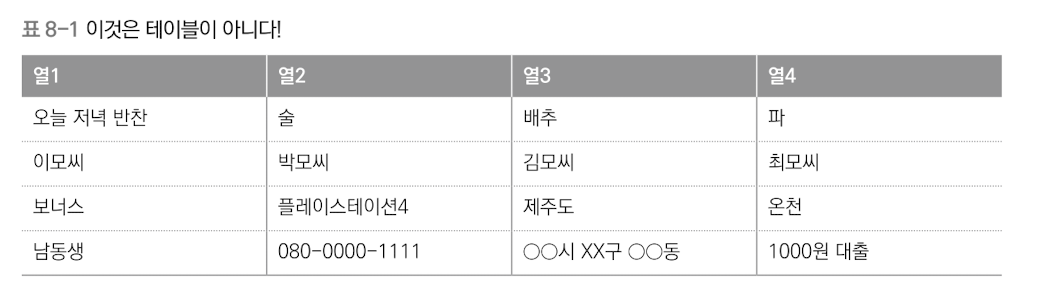
테이블과 표는 매우 닮아서 양쪽 모두 행과 열로 된 데이터 구조이다.
하지만 테이블에는 '테이블은 공통적인 요소의 집합이다'라는 조건이 추가된다.
쉽게 표현하면, 테이블은 관련성 없는 것이 이것저것 모여서는 안된다는 것이다.
(표 8-1은 테이블이 아니다)
테이블이란 각각의 행이 어떤 공통적인 특징을 가진 집합이어야한다.

위 예는 테이블이다.
이 예에서 테이블은 '원자의 집합'을 나타낸다.
이처럼 관계형 데이터베이스에서 테이블은 '어떤 공통의 속성을 가진 것의 집합'을 나타내야한다.
이것이 테이블 설계의 제1 규칙이다.
이 규칙을 데이터베이스 세계에서는 '테이블명은 반드시 복수형이나 집합명사로 표현해야 한다'라고 표현한다.
위 규칙에 따르면 위 테이블은 'Atoms'라고 할 수가 있다.
테이블 설계 규칙
테이블 설계란 '테이블은 현실 세계의 개념이나 집합을 나타낸 것'이라는 규칙에 충실하기만 한다면 어려울 것이 없다.
물론 테이블 수가 증가하거나 테이블 간 관계성이 복잡해진다면 기술적으로 복잡해진다.
위에서 말한 것처럼, 테이블 제1 규칙은
'테이블이란 공통점을 가진 사물의 집합'이다.
하지만 테이블의 구성 패턴(구분 패턴)은 인간의 인식을 반영하기때문에 자의적으로 개념을 만들어서 집합을 나눈다면
인간의 자유로운 사고도 반영한다는 것이 된다.
[가장 상위의 개념집합으로 정리한다]
이런 경우 기본 규칙은 '가장 상위의 개념집합'으로 정리하는 것이다.
Java와 같은 객체지향 언어에 비유하자면,
테이블은 클래스에 해당하고 각 행은 거기서 실체화된 인스턴스에 해당한다.
다만, 객체지향 언어의 클래스와는 달리 테이블은 메소드를 가지고 있지 않기때문에 주체적으로 액션을 일으키지 않는다.
(PostgreSQL은 테이블에 대해 클래스와 같은 상속을 정의할 수도 있다)
[기본키 할당은 기본]
테이블의 기본키를 설정하는 것은 테이블 설계 원칙의 하나이다.
이것은 '한 개 테이블의 내용에는 중복 행을 허용하지 않는다'라는 의미가 된다.
중복 행을 허용하는 것은 매우 위험하므로, 테이블에서는 반드시 레코드를 1행으로 특정할 수 있는 정보가 필요하다.
이것이 기본키 열이다.
기본키는 한 개의 테이블에 반드시 한 개만 존재해야한다.
회원 테이블이라면 '회원 ID'나 '회원번호'같은 절대로 중복하지 않는 숫자나 문자열에 의한 기본키(Primary Key)를 할당하는 것이 일반적이다.
이러한 Primary Key를 표 형식으로 나타낼 때는 기본키의 열 명에 underlined하여 표현한다.
기본키의 값이 바뀌면 곤란한데, 그 이유는
- 변경 후 값의 유일성을 보증할 수 없음
- 과거 데이터와의 결합이 어려움
이 있다.
결국 데이터 관리는 '장기적으로 정합성을 얻는 노력을 해야하는' 것이다.
다시 말하면, 테이블 설계는 데이터가 '정적'이지 않고 '동적'임을 전제로 생각해야한다.