
1. 검색하기
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
from selenium import webdriver
path = "C:/chromedriver/chromedriver.exe" #웹드라이버가 있는 경로
driver = webdriver.Chrome(path) #웹드라이버가 있는 경로에서 Chrome을 가져와 실행-> driver변수
driver.get('https://www.google.com') #driver변수를 이용해 원하는 url 접속
elem = driver.find_element_by_name("q") #q라는 요소를 찾아 반환(검색창)
elem.clear() #검색창의 default값 비우기
elem.send_keys("Selenium") #현재 집중된 요소(elem)에 key를 날리기
elem.submit() #form제출하기(검색하기)
|
cs |
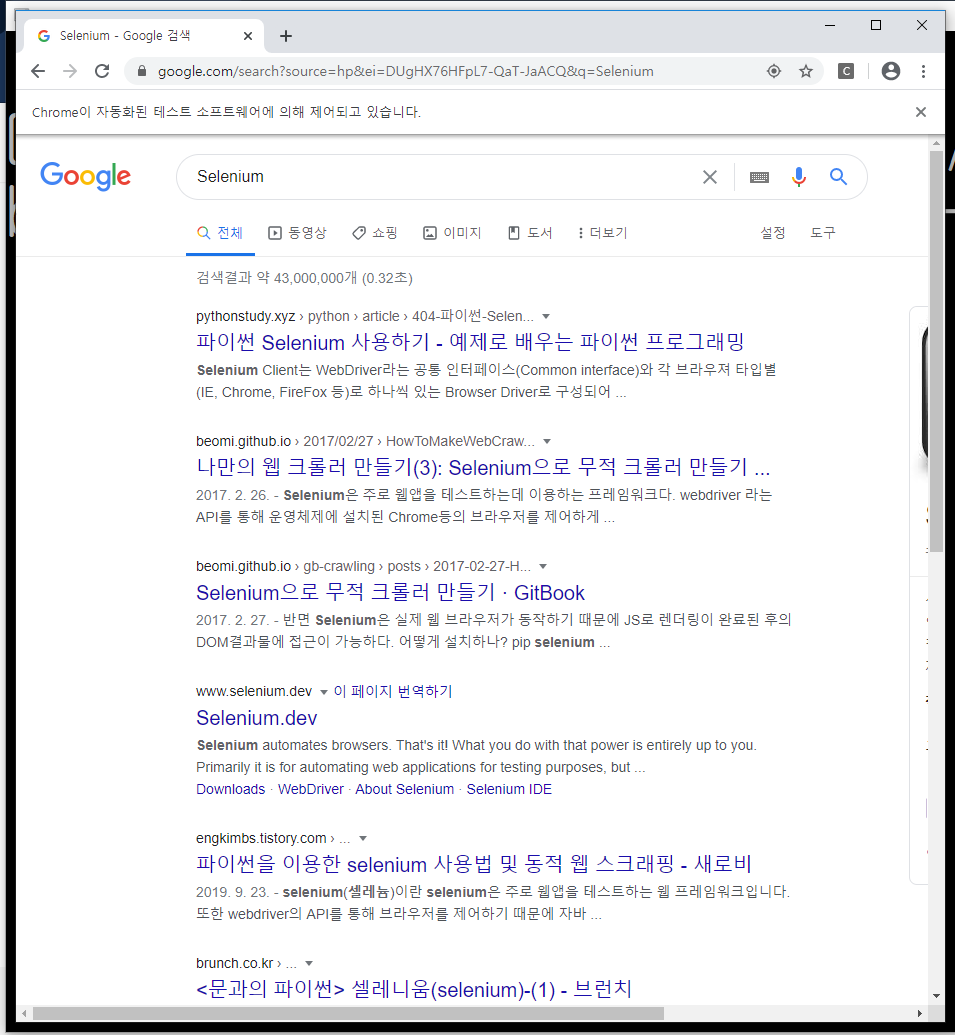
검색창에 입력하는 것 이외에도 다양한 API는 아래의 링크에 적혀있다.
https://selenium-python.readthedocs.io/api.html#module-selenium.webdriver.chrome.service
위 링크에서 "Remote Web Driver"를 참고하였다.
2. 이미지 크롤링
목표 : 힙합퍼사이트에서 반팔티-인기순의 이미지들을 크롤링 해 온 뒤, 다운받는 것!!
저번 실습1 때 배웠던 것과 아래 링크를 통해 실습한 것을 합쳐 해보았다.
- 참고 : https://www.youtube.com/watch?v=HJN28B7OSzw
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
from selenium import webdriver
path = "C:/chromedriver/chromedriver.exe" #웹드라이버가 있는 경로
driver = webdriver.Chrome(path) #웹드라이버가 있는 경로에서 Chrome을 가져와 실행-> driver변수
driver.get('https://www.hiphoper.com/clothing/list?_ct=tshirts') #driver변수를 이용해 원하는 url 접속
imgs = driver.find_elements_by_css_selector('img.pos_center') #css selector를 이용해서 'tag이름.class명'의 순으로 인자를 전달
#이미지들을 가져와 imgs에 저장
for img in imgs: #모든 이미지들을 탐색
print(img.get_attribute('src')) #이미지 주소를 print
|
cs |
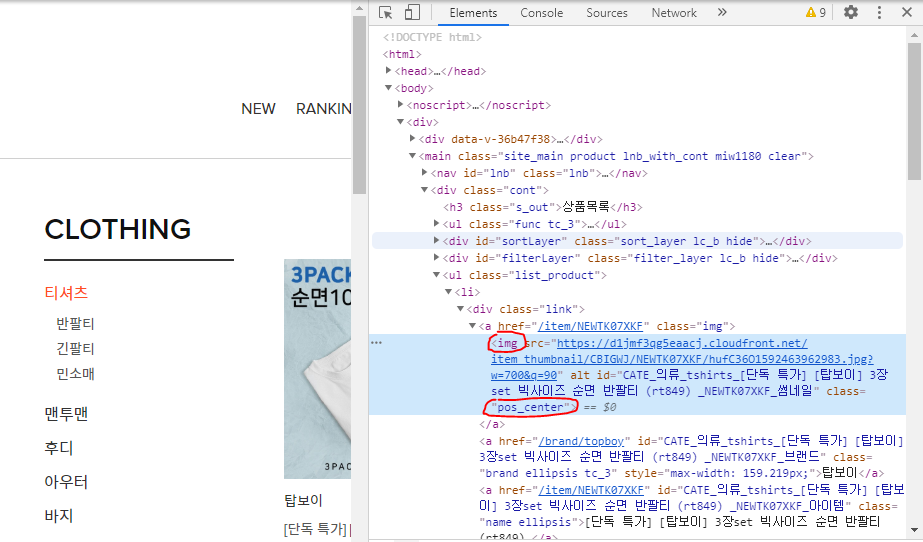
현재 힙합퍼 사이트에서 반팔-인기순 페이지에서 코드를 확인해보면
img태그들 중에서 class가 'pos_center'인 이미지들은 상품의 이미지를 의미하고 있었다.
그러므로 9번째 줄의 코드에서 'img.pos_center'가 만들어진다.
위 코드를 실행하면, 아래와 같이 이미지들의 src가 프린트된다.
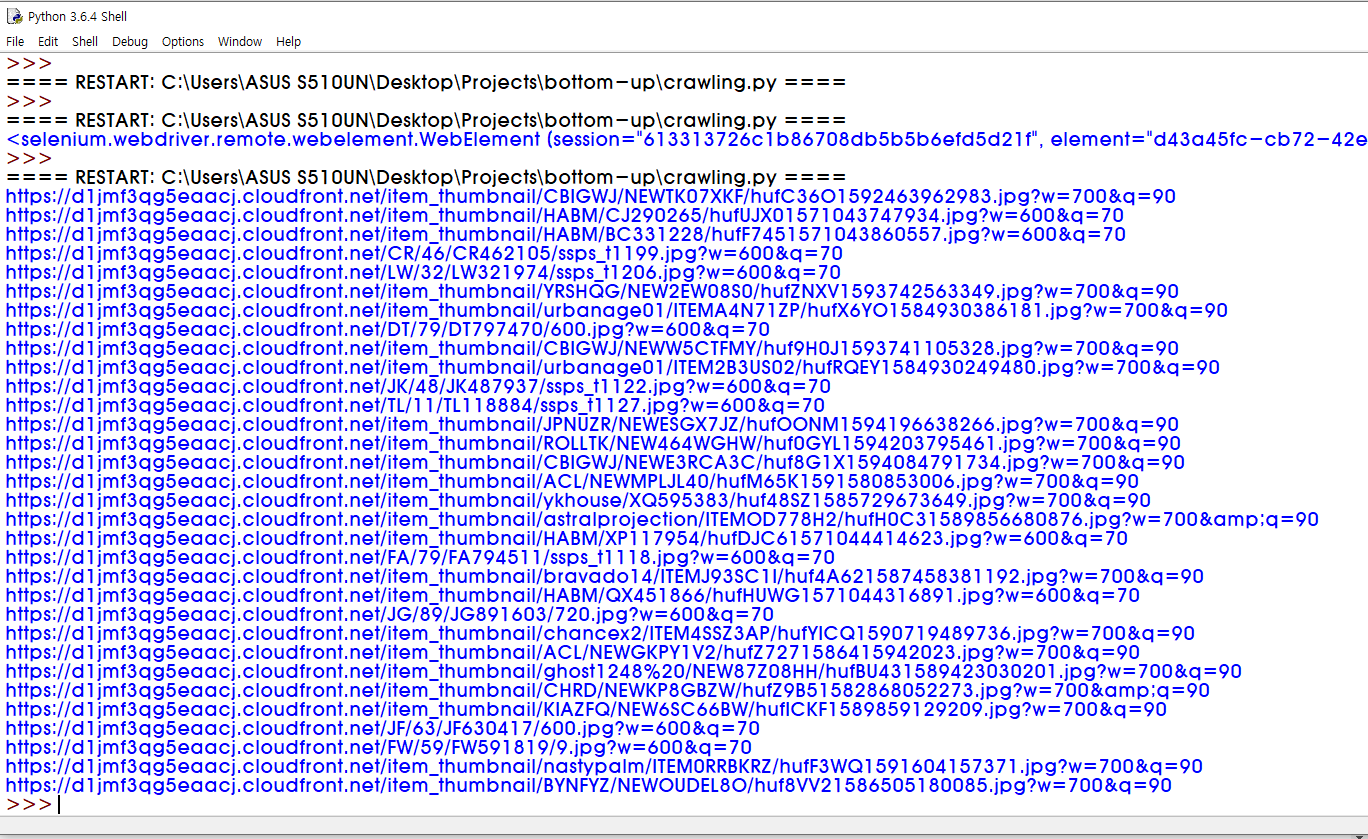
많아 보이지만 아직 한참 더 필요하다!!ㅎㅎ
3. 크롤링한 이미지 다운로드하기
해야하는 것
- 이미지를 저장 할 폴더 생성
- 다운로드 시, 확장자명과 파일명 설정
- 폴더에 이미지 다운로드
1. 폴더 생성
|
1
2
3
4
5
6
7
|
#폴더생성
import os
img_folder_path = 'C:/Users/ASUS S510UN/Desktop/Projects/bottom-up/imgs' #이미지 저장 폴더
if not os.path.isdir(img_folder_path): #없으면 새로 생성
os.mkdir(img_folder_path)
|
폴더를 생성하는 코드이다.
이미지를 저장할 경로를 지정해주고, 없으면 새로 생성!!
2. 이미지 다운로드
|
1
2
3
4
5
6
7
8
|
#이미지 다운로드
from urllib.request import urlretrieve
for index, link in enumerate(result): #리스트에 있는 원소만큼 반복, 인덱스는 index에, 원소들은 link를 통해 접근 가능
start = link.rfind('.') #.을 시작으로
end = link.rfind('?') #?를 끝으로
filetype = link[start:end] #확장자명을 잘라서 filetype변수에 저장 (ex -> .jpg)
urlretrieve(link, './imgs/{}{}'.format(index, filetype)) #link에서 이미지 다운로드, './imgs/'에 파일명은 index와 확장자명으로
|
2의 이미지 크롤링에서 코드 오류가 있어서 바꾸었는데,
오류는 imgs리스트를 그대로 쓰려하니, 걔들은 src의 객체라서 추출이 안된다?? 이런 내용이었다.
그래서 동영상에 나온 것처럼 result라는 리스트를 하나 만들어 src를 추출해 넣어주었다.
전체 코드는 아래에 있음
src="https://d1jmf3qg5eaacj.cloudfront.net/item_thumbnail/CBIGWJ/NEWTK07XKF/hufC36O1592463962983.jpg?w=700&q=90"
src를 보면 위와 같은 형태이다.
여기에서 확장자명인 .jpg를 뽑아내기 위해서는
.부터 ?의 인덱스를 알아내 잘라내면 된다.
(.부터 ? 앞까지 자름)
자른 텍스트를 filetype에 넣어주고
urlretrieve를 이용해 이미지를 다운받아주는데,
파일명은 index+filetype으로 한다!! 그럼 예를 들면....1.jpg 이렇게 되겠지??응응
3. 전체코드
{kind=link}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
|
#Chrome 켠 후, 이미지 가져옴
from selenium import webdriver
path = "C:/chromedriver/chromedriver.exe" #웹드라이버가 있는 경로
driver = webdriver.Chrome(path) #웹드라이버가 있는 경로에서 Chrome을 가져와 실행-> driver변수
driver.get('https://www.hiphoper.com/clothing/list?_ct=tshirts') #driver변수를 이용해 원하는 url 접속
imgs = driver.find_elements_by_css_selector('img.pos_center') #css selector를 이용해서 'tag이름.class명'의 순으로 인자를 전달
result = [] #웹 태그에서 attribute 중 src만 담을 리스트
for img in imgs: #모든 이미지들을 탐색
#print(img.get_attribute('src')) #이미지 주소를 print
result.append(img.get_attribute('src')) #이미지 src만 모아서 리스트에 저장
#폴더생성
import os
img_folder_path = 'C:/Users/ASUS S510UN/Desktop/Projects/bottom-up/imgs' #이미지 저장 폴더
if not os.path.isdir(img_folder_path): #없으면 새로 생성
os.mkdir(img_folder_path)
#이미지 다운로드
from urllib.request import urlretrieve
for index, link in enumerate(result): #리스트에 있는 원소만큼 반복, 인덱스는 index에, 원소들은 link를 통해 접근 가능
start = link.rfind('.') #.을 시작으로
end = link.rfind('?') #?를 끝으로
filetype = link[start:end] #확장자명을 잘라서 filetype변수에 저장 (ex -> .jpg)
urlretrieve(link, './imgs/{}{}'.format(index, filetype)) #link에서 이미지 다운로드, './imgs/'에 파일명은 index와 확장자명으로
|
전체 코드는 바로 이거!!
13과 17라인에 result를 추가해주었다!!
코드를 실행하면,
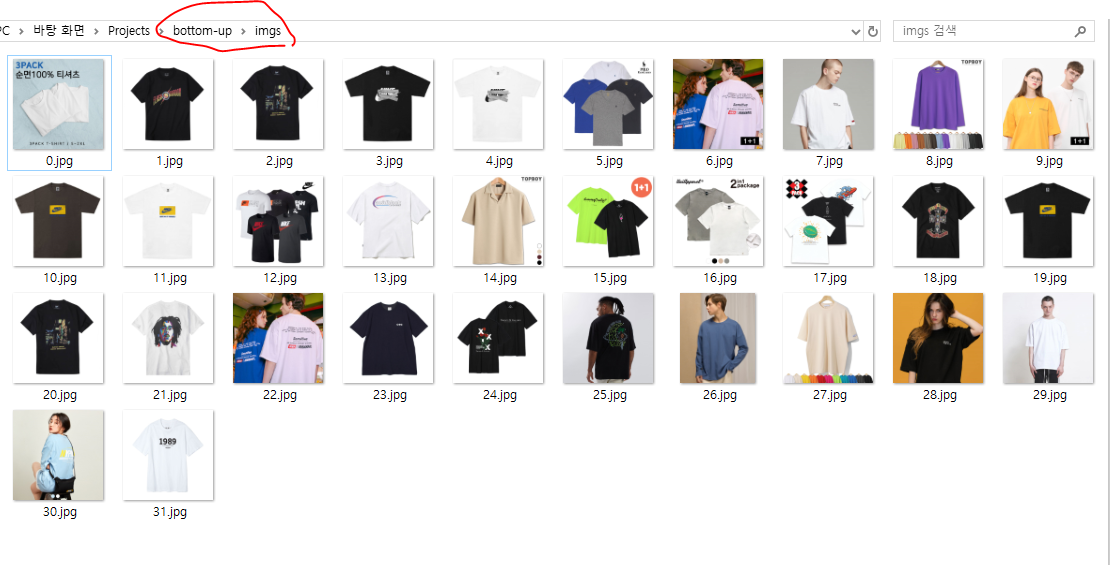
원하는 페이지에서 이미지들이 모아졌다.
근데 참고로 이건 '인기순'에서 1페이지기때문에.....
전체 페이지를 모두 크롤링하려면 다른 처리가 필요하다!!
이건 다음 글에서!!!
성공해서 기분좋다! ㅎㅎ
'Project > 2020 Bottom-up' 카테고리의 다른 글
| 1] 웹 Crawling 만들기 : Selenium(설치와 실습1) (0) | 2020.07.08 |
|---|
1. 검색하기
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
from selenium import webdriver
path = "C:/chromedriver/chromedriver.exe" #웹드라이버가 있는 경로
driver = webdriver.Chrome(path) #웹드라이버가 있는 경로에서 Chrome을 가져와 실행-> driver변수
driver.get('https://www.google.com') #driver변수를 이용해 원하는 url 접속
elem = driver.find_element_by_name("q") #q라는 요소를 찾아 반환(검색창)
elem.clear() #검색창의 default값 비우기
elem.send_keys("Selenium") #현재 집중된 요소(elem)에 key를 날리기
elem.submit() #form제출하기(검색하기)
|
cs |
검색창에 입력하는 것 이외에도 다양한 API는 아래의 링크에 적혀있다.
https://selenium-python.readthedocs.io/api.html#module-selenium.webdriver.chrome.service
위 링크에서 "Remote Web Driver"를 참고하였다.
2. 이미지 크롤링
목표 : 힙합퍼사이트에서 반팔티-인기순의 이미지들을 크롤링 해 온 뒤, 다운받는 것!!
저번 실습1 때 배웠던 것과 아래 링크를 통해 실습한 것을 합쳐 해보았다.
- 참고 : https://www.youtube.com/watch?v=HJN28B7OSzw
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
from selenium import webdriver
path = "C:/chromedriver/chromedriver.exe" #웹드라이버가 있는 경로
driver = webdriver.Chrome(path) #웹드라이버가 있는 경로에서 Chrome을 가져와 실행-> driver변수
driver.get('https://www.hiphoper.com/clothing/list?_ct=tshirts') #driver변수를 이용해 원하는 url 접속
imgs = driver.find_elements_by_css_selector('img.pos_center') #css selector를 이용해서 'tag이름.class명'의 순으로 인자를 전달
#이미지들을 가져와 imgs에 저장
for img in imgs: #모든 이미지들을 탐색
print(img.get_attribute('src')) #이미지 주소를 print
|
cs |
현재 힙합퍼 사이트에서 반팔-인기순 페이지에서 코드를 확인해보면
img태그들 중에서 class가 'pos_center'인 이미지들은 상품의 이미지를 의미하고 있었다.
그러므로 9번째 줄의 코드에서 'img.pos_center'가 만들어진다.
위 코드를 실행하면, 아래와 같이 이미지들의 src가 프린트된다.
많아 보이지만 아직 한참 더 필요하다!!ㅎㅎ
3. 크롤링한 이미지 다운로드하기
해야하는 것
- 이미지를 저장 할 폴더 생성
- 다운로드 시, 확장자명과 파일명 설정
- 폴더에 이미지 다운로드
1. 폴더 생성
|
1
2
3
4
5
6
7
|
#폴더생성
import os
img_folder_path = 'C:/Users/ASUS S510UN/Desktop/Projects/bottom-up/imgs' #이미지 저장 폴더
if not os.path.isdir(img_folder_path): #없으면 새로 생성
os.mkdir(img_folder_path)
|
폴더를 생성하는 코드이다.
이미지를 저장할 경로를 지정해주고, 없으면 새로 생성!!
2. 이미지 다운로드
|
1
2
3
4
5
6
7
8
|
#이미지 다운로드
from urllib.request import urlretrieve
for index, link in enumerate(result): #리스트에 있는 원소만큼 반복, 인덱스는 index에, 원소들은 link를 통해 접근 가능
start = link.rfind('.') #.을 시작으로
end = link.rfind('?') #?를 끝으로
filetype = link[start:end] #확장자명을 잘라서 filetype변수에 저장 (ex -> .jpg)
urlretrieve(link, './imgs/{}{}'.format(index, filetype)) #link에서 이미지 다운로드, './imgs/'에 파일명은 index와 확장자명으로
|
2의 이미지 크롤링에서 코드 오류가 있어서 바꾸었는데,
오류는 imgs리스트를 그대로 쓰려하니, 걔들은 src의 객체라서 추출이 안된다?? 이런 내용이었다.
그래서 동영상에 나온 것처럼 result라는 리스트를 하나 만들어 src를 추출해 넣어주었다.
전체 코드는 아래에 있음
src="https://d1jmf3qg5eaacj.cloudfront.net/item_thumbnail/CBIGWJ/NEWTK07XKF/hufC36O1592463962983.jpg?w=700&q=90"
src를 보면 위와 같은 형태이다.
여기에서 확장자명인 .jpg를 뽑아내기 위해서는
.부터 ?의 인덱스를 알아내 잘라내면 된다.
(.부터 ? 앞까지 자름)
자른 텍스트를 filetype에 넣어주고
urlretrieve를 이용해 이미지를 다운받아주는데,
파일명은 index+filetype으로 한다!! 그럼 예를 들면....1.jpg 이렇게 되겠지??응응
3. 전체코드
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
|
#Chrome 켠 후, 이미지 가져옴
from selenium import webdriver
path = "C:/chromedriver/chromedriver.exe" #웹드라이버가 있는 경로
driver = webdriver.Chrome(path) #웹드라이버가 있는 경로에서 Chrome을 가져와 실행-> driver변수
driver.get('https://www.hiphoper.com/clothing/list?_ct=tshirts') #driver변수를 이용해 원하는 url 접속
imgs = driver.find_elements_by_css_selector('img.pos_center') #css selector를 이용해서 'tag이름.class명'의 순으로 인자를 전달
result = [] #웹 태그에서 attribute 중 src만 담을 리스트
for img in imgs: #모든 이미지들을 탐색
#print(img.get_attribute('src')) #이미지 주소를 print
result.append(img.get_attribute('src')) #이미지 src만 모아서 리스트에 저장
#폴더생성
import os
img_folder_path = 'C:/Users/ASUS S510UN/Desktop/Projects/bottom-up/imgs' #이미지 저장 폴더
if not os.path.isdir(img_folder_path): #없으면 새로 생성
os.mkdir(img_folder_path)
#이미지 다운로드
from urllib.request import urlretrieve
for index, link in enumerate(result): #리스트에 있는 원소만큼 반복, 인덱스는 index에, 원소들은 link를 통해 접근 가능
start = link.rfind('.') #.을 시작으로
end = link.rfind('?') #?를 끝으로
filetype = link[start:end] #확장자명을 잘라서 filetype변수에 저장 (ex -> .jpg)
urlretrieve(link, './imgs/{}{}'.format(index, filetype)) #link에서 이미지 다운로드, './imgs/'에 파일명은 index와 확장자명으로
|
전체 코드는 바로 이거!!
13과 17라인에 result를 추가해주었다!!
코드를 실행하면,
원하는 페이지에서 이미지들이 모아졌다.
근데 참고로 이건 '인기순'에서 1페이지기때문에.....
전체 페이지를 모두 크롤링하려면 다른 처리가 필요하다!!
이건 다음 글에서!!!
성공해서 기분좋다! ㅎㅎ
'Project > 2020 Bottom-up' 카테고리의 다른 글
| 1] 웹 Crawling 만들기 : Selenium(설치와 실습1) (0) | 2020.07.08 |
|---|